(a) |
(b) |
The Gram-matrix for the CNN is computed as the time-averaged correlations between the feature maps from the filters. Specifically, each element of the Gram-matrix of the CNN is defined as
| (1) |
where, is the total number of time frames, and are the feature maps of dimension of the and the filters, where and range from 1 to the number of filters,, i.e. 512. The resulting Gram-matrix, thus, has dimensions at the output of each CNN, and the Gram-matrix of the CNN consists of dot products of the feature maps, written as,
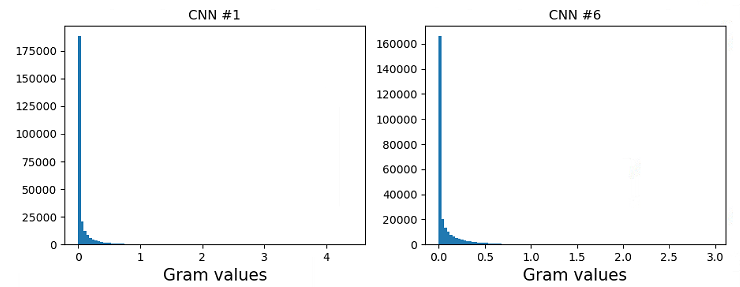
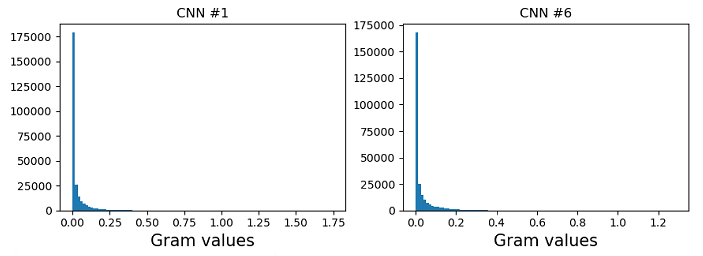
Figure 1 shows the histogram of the values of the Gram matrices from the first () and the sixth () CNNs from a Frequency Modulation (FM) signal at a particular carrier frequency, modulation frequency, and modulation index and a water-filling sound at a particular fill level in a container. Although the range of values in these Gram-matrices are different (x-axis), it is evident from the histograms of the Gram-matrices of both these textures that they are sparse with most values of the matrix being close to zero. This suggests that non-zero values of the correlation between feature maps are sparsely located.
|
(a) |
|
(b) |
We divide each row of the Gram matrix from equation 2 into segments of length , as shown in equation 3, where in our experiments, we use .
The Gram vector of dimension is computed as a row aggregated average vector over all the Gram matrices of a given audio texture. The first element of the Gram vector of the Gram-matrix from the CNN is computed as
| (4) |
Similarly, the last element of this vector for the Gram-matrix from the CNN is computed as,
| (5) |
Therefore, the overall gram vector of dimension is the element-wise mean of these vectors over the Gram matrices of an audio texture corresponding to the CNNs, given as
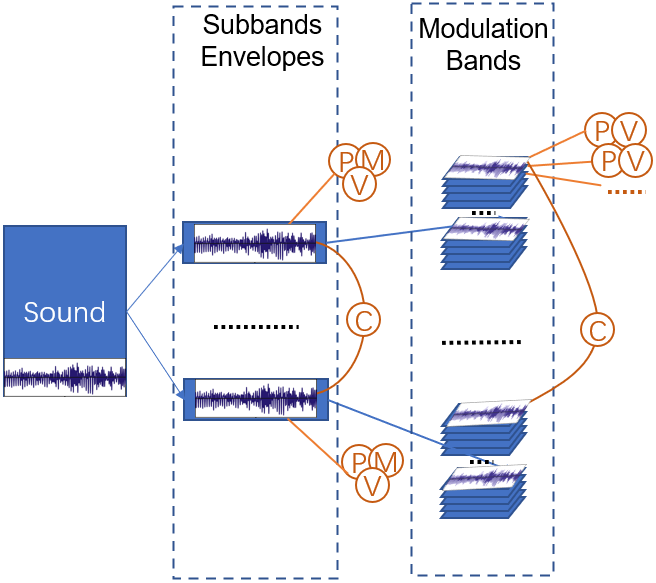
The implementation uses a cochlear filterbank with 36 Gammatone filters, with Hilbert transform to compute the envelopes, and then compresses the envelopes with an exponential rate of 0.3 on each element in the matrix [1]. The modulation filterbank with 20 filters is applied on each envelope, thus generating 3620 modulation bands.
For each sound , seven sets of statistics are computed, denote them by where ,
The algorithm, thus, generates 6,432 statistical parameters.
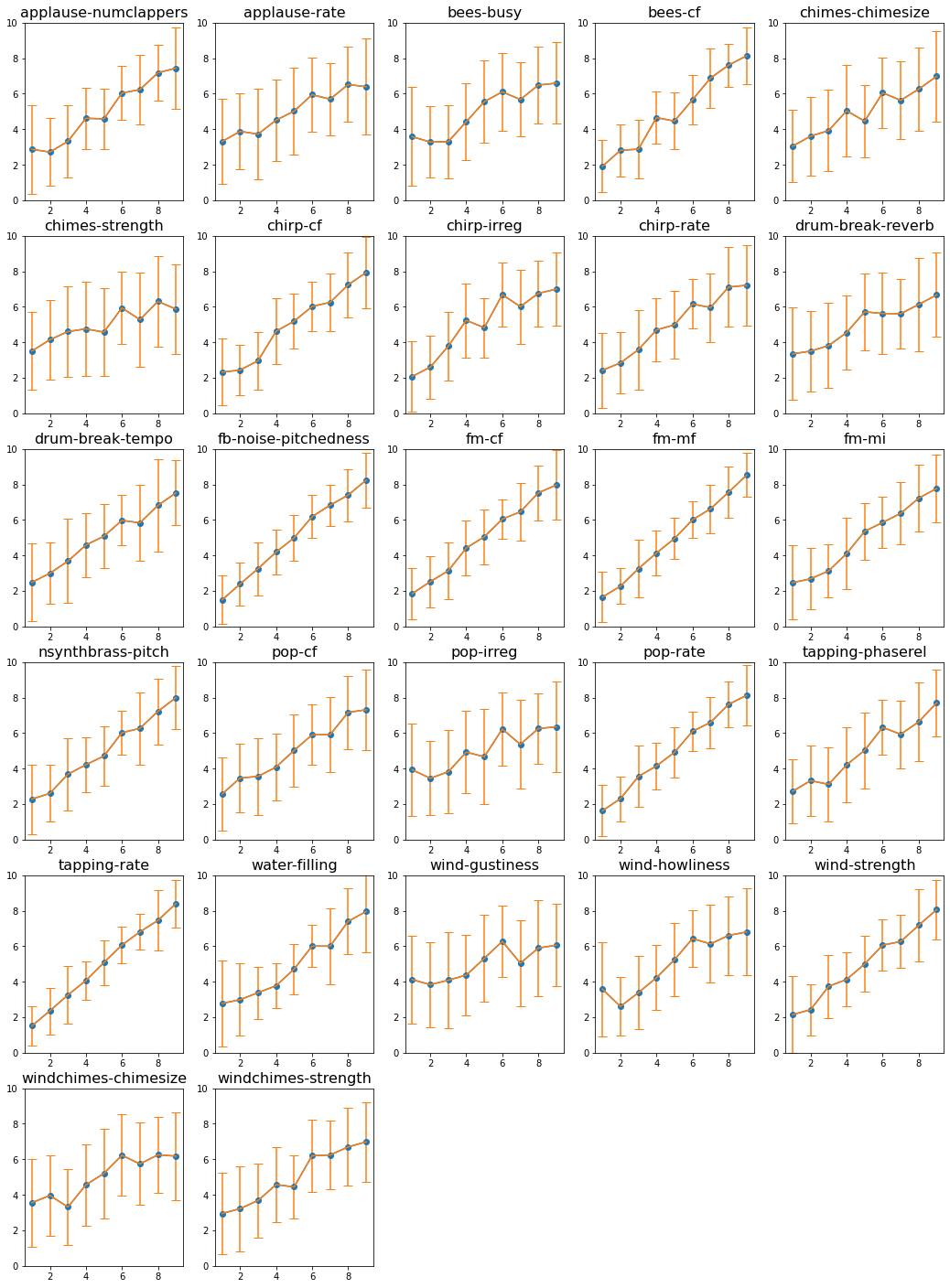
The trends of subjective responses and objective metrics can be observed for the three sets of audio textures in Figures 3 (pitched), 4 (rhythmic), and 5 (others).
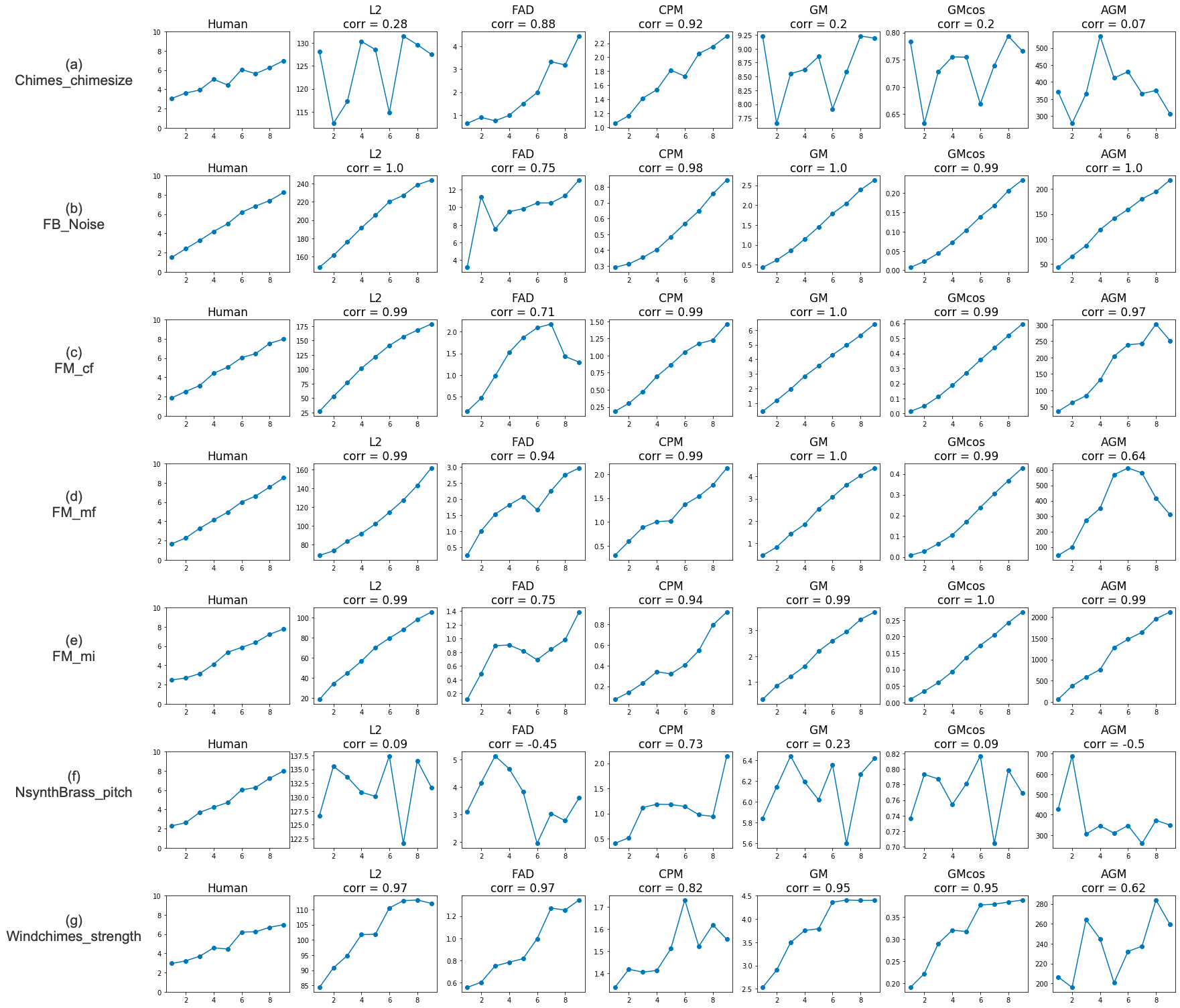
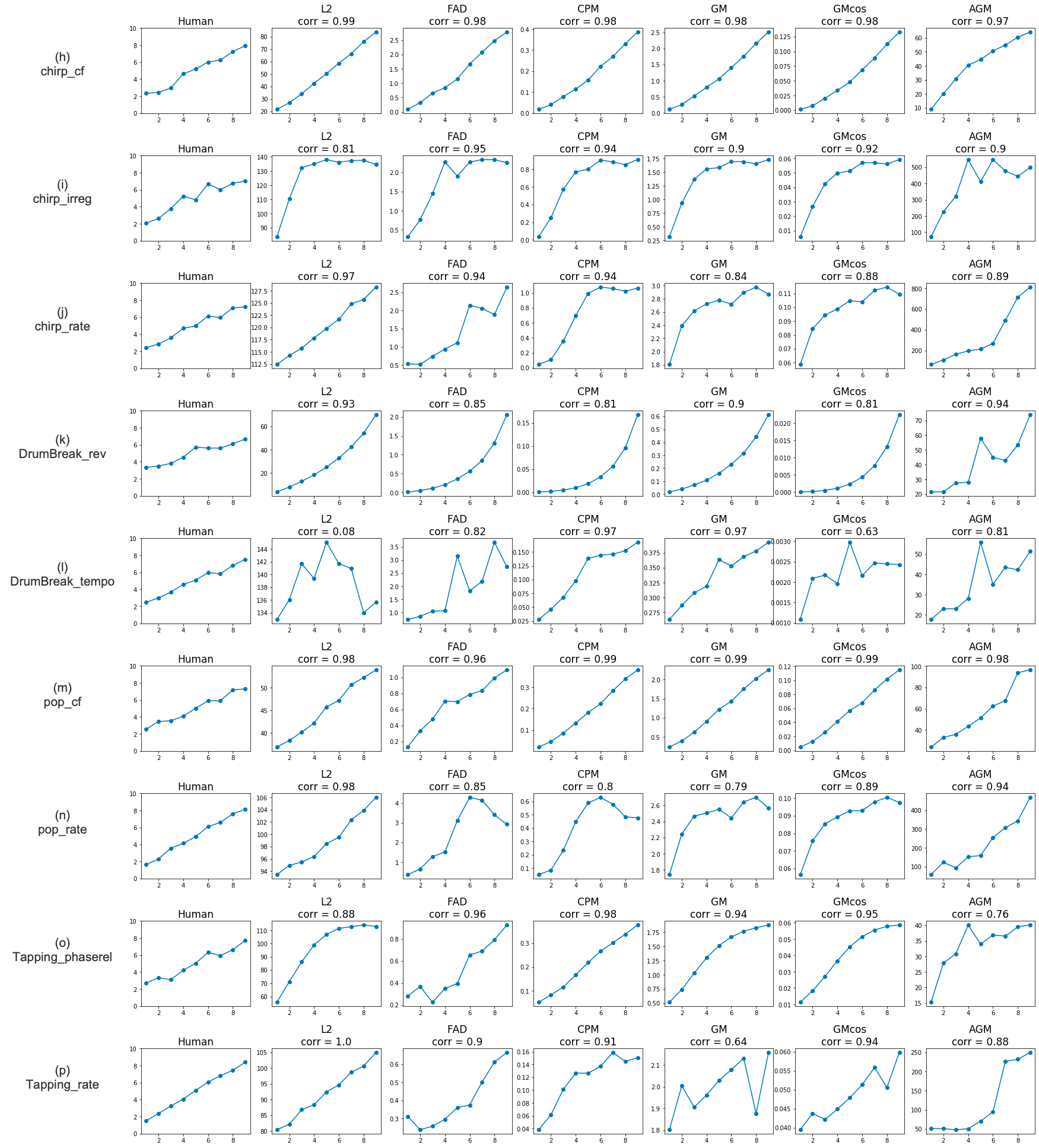
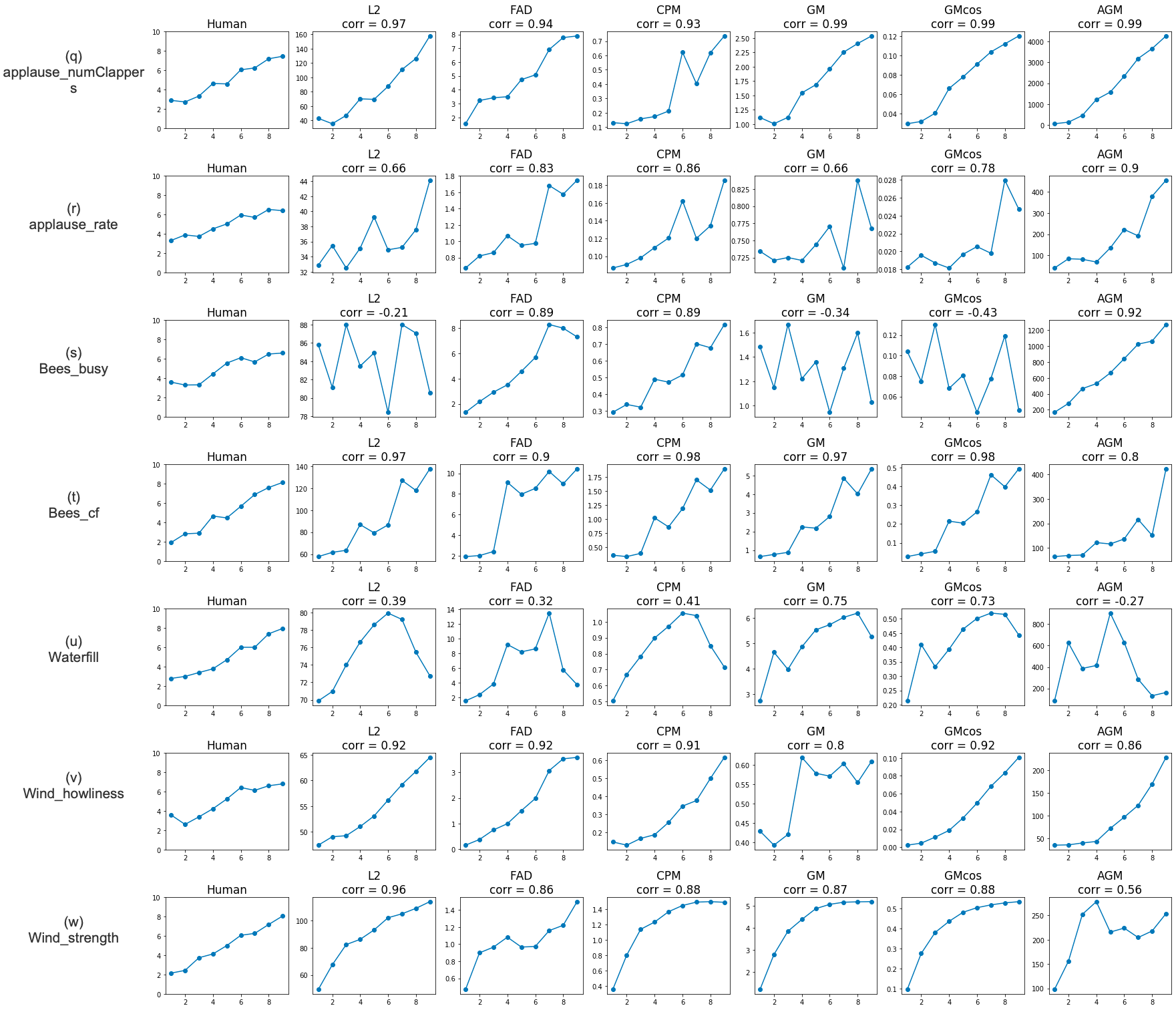
The rank-order responses obtained from the human listening tests are plotted in Figure 6.